Kun Zhoua, Berrak Sismanb,a, Mingyang Zhanga, Haizhou Lia zhoukun@u.nus.edu berraksisman@u.nus.edu elezmin@nus.edu.sg haizhou.li@nus.edu.sg
a Dept. of Electrical and Computer Engineering, National University of Singapore b Information Systems Technology and Design, Singapore University of Technology and Design
----------------------------> Model Architecture <-----------------------
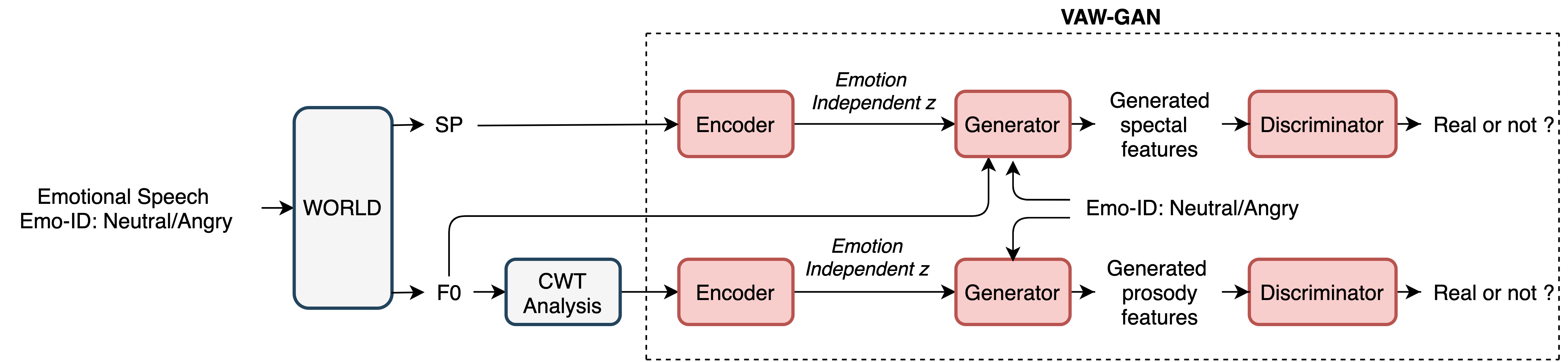
Fig.1 The training phase of the proposed VAW-GAN-based emotional voice conversion framework with WORLD vocoder. Red boxes are involved in the training, while grey boxes are not.
Fig.2 The run-time conversion phase of the proposed VAW-GAN-based emotional voice conversion framework with WORLD vocoder. Blue boxes represent the networks which have been trained during the training phase.